






























![[Vidéo] 45 moments où Dame Nature s’est déchainée, capturés par caméra](https://cdn-0.buzzpanda.fr/wp-content/uploads/2024/10/45-fois-o-650-360x180.jpg)


















L’écriture cunéiforme représente l’un des plus anciens systèmes d’écriture de l’histoire de l’humanité. Les archéologues font remonter ses origines à 3 400 avant notre ère, soit il y a près de 5 400 ans. Ce système a perduré pendant une période exceptionnellement longue de plus de 3 000 ans. Au fil des découvertes, les chercheurs ont mis au jour des milliers de textes rédigés en cunéiforme dans les langues sumérienne et akkadienne. Aujourd’hui, une avancée technologique majeure permet à un réseau de neurones artificiels de traduire ces textes anciens de manière fluide.

L’héritage d’un langage antique et mystérieux
L’akkadien figure parmi les plus anciennes langues sémitiques connues, une famille linguistique qui englobe des langues modernes telles que l’arabe et l’hébreu. Il était parlé en Mésopotamie antique, principalement au sein de l’Empire akkadien, situé dans une région correspondant aujourd’hui à certaines parties de l’Irak et du nord-est de la Syrie. Cette langue tire son nom de la cité antique d’Akkad, l’un des centres névralgiques de cette civilisation.
L’akkadien remplissait des fonctions très variées, allant des documents administratifs et juridiques aux œuvres littéraires et textes scientifiques. Rédigé en écriture cunéiforme sur des tablettes d’argile, son déchiffrement au XIXe siècle a ouvert une fenêtre inédite sur le monde antique, offrant aux spécialistes de précieuses informations sur l’histoire, la culture et les avancées scientifiques de l’époque.
De son côté, le sumérien est l’une des plus anciennes langues connues au monde. Il a la particularité d’être un isolat linguistique, ce qui signifie qu’on ne lui connaît aucune langue apparentée. Il était parlé dans l’antique Sumer, une région située dans la partie méridionale de l’actuel Irak. Les Sumériens sont reconnus pour avoir fondé l’une des premières civilisations au monde vers 4 500 avant notre ère, une société qui a prospéré jusqu’à environ 2 000 avant notre ère.
Ces deux langues, à l’instar de plusieurs autres, utilisaient le système d’écriture cunéiforme. Cependant, la traduction de ces signes s’est révélée être un défi colossal.
Le déchiffrement complet du cunéiforme a nécessité plus de 200 ans d’efforts, s’étalant de 1802 à 2022. Cette épopée a débuté avec la célèbre inscription de Behistun. Découverte en Iran et datant de l’époque du roi perse Darius Ier (550 avant notre ère), cette inscription multilingue comportait trois types d’écritures : le vieux perse, l’élamite et le cunéiforme akkadien. Le vieux perse a été déchiffré en premier, fournissant ainsi les clés nécessaires pour comprendre les deux autres.
Les chercheurs ont progressivement travaillé à la compréhension du cunéiforme, et après de multiples révélations et un travail acharné, ils ont finalement acquis une solide maîtrise de cette écriture. Toutefois, pour certains scientifiques, cela ne suffisait pas. Désireux de rendre la traduction du cunéiforme plus accessible, ils se sont tournés vers l’intelligence artificielle.
Quand le cunéiforme rencontre l’intelligence artificielle
Ces dernières années, les traductions linguistiques ont connu des progrès fulgurants, et l’intelligence artificielle accélère considérablement cette tendance à l’automatisation. Dans le cadre d’une nouvelle étude, Shai Gordin et ses collègues de l’Université d’Ariel ont mis au point un modèle d’intelligence artificielle capable de traduire automatiquement des textes akkadiens écrits en cunéiforme vers l’anglais. Bien que cette technologie ne soit pour l’instant disponible que pour cette langue spécifique, les résultats demeurent remarquables.
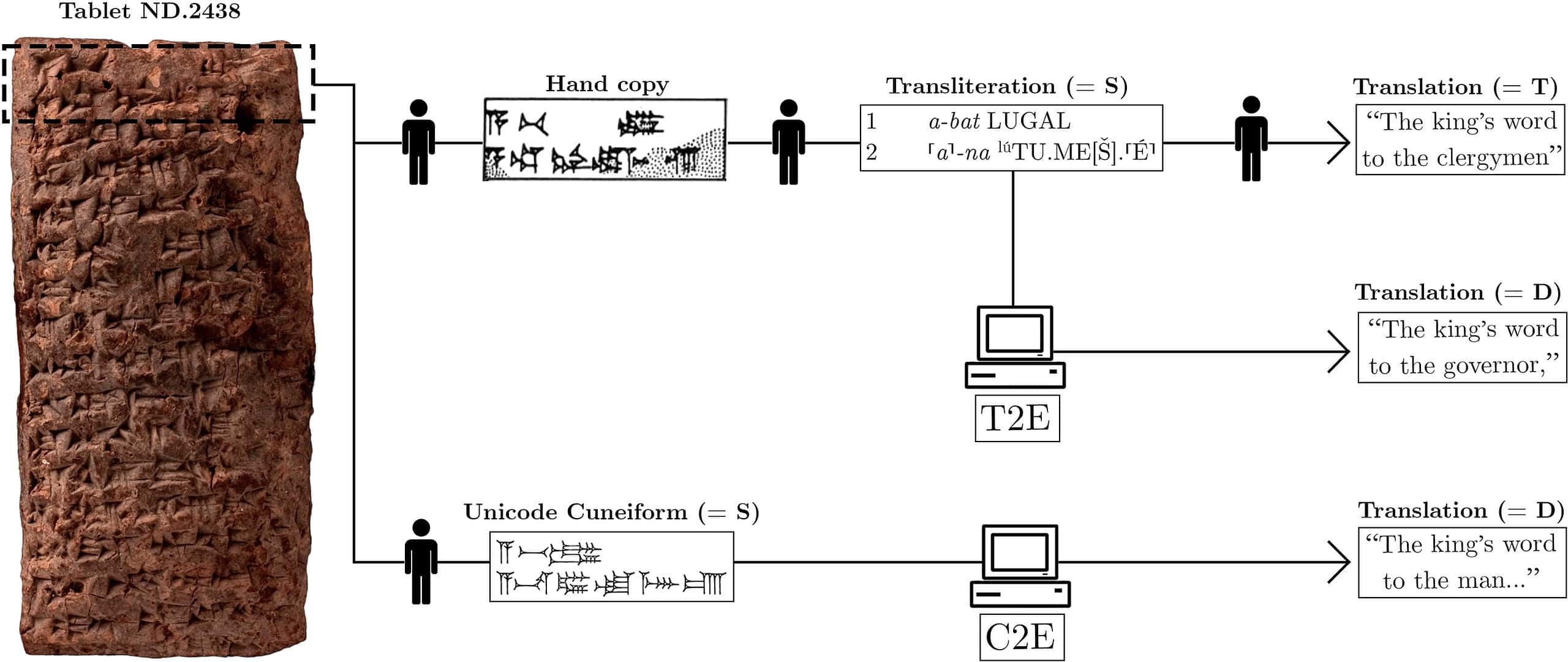
Pour cette recherche, les scientifiques ont entraîné deux versions du modèle. La première traduit l’akkadien à partir de ses représentations en caractères latins, un processus appelé translittération. La seconde version effectue la traduction directement à partir des représentations Unicode des signes cunéiformes, qui constituent le format standard pour la numérisation de cette écriture.
Une évaluation rigoureuse des performances
La première version du modèle, basée sur la translittération, a fourni les meilleurs résultats lors de l’étude, atteignant un score de 37,47 selon la métrique BLEU4.
Le score Bilingual Evaluation Understudy (BLEU) est un outil de mesure utilisé pour évaluer la qualité des traductions générées par des machines. Il évalue la proximité entre une traduction automatique et un ensemble de traductions de référence réalisées par des humains. Ce score varie de 0 à 1 (ou de 0 à 100), les valeurs les plus élevées indiquant de meilleures traductions. Même les traducteurs humains expérimentés n’atteignent généralement pas le score parfait de 100. Pour une langue aussi complexe que le cunéiforme, un score de 37 est considéré comme largement suffisant pour obtenir une traduction de bonne qualité.


Les limites actuelles et les perspectives d’avenir
Le modèle obtient ses meilleurs résultats sur des phrases de longueur courte à moyenne. À mesure que les phrases s’allongent, l’intelligence artificielle peine à saisir l’intégralité du contexte, bien que les chercheurs précisent que ce point pourra être amélioré à l’avenir grâce à un entraînement supplémentaire. Une autre limite réside dans la tendance du modèle à produire des « hallucinations » : il génère parfois des résultats syntaxiquement corrects mais totalement déconnectés du sens du texte original. Ce phénomène est d’ailleurs commun à d’autres systèmes d’intelligence artificielle actuels.
L’exemple suivant illustre parfaitement ce problème :
Phrase 2 753
Source : UD 21-KAM2 LUGAL ina E2-DINGIR E2-DINGIR la ur-rad
Traduction humaine : « Le 21e jour, le roi ne descend pas à la Maison de Dieu. »
Traduction automatique : « Le 21e jour, le roi descend à la Maison de Dieu. »
Dans ce cas précis, l’intelligence artificielle a correctement traduit la majeure partie du contenu. Cependant, une erreur, probablement survenue lors du nettoyage des données d’entraînement, a conduit le modèle à omettre la négation, modifiant ainsi radicalement le sens de la phrase.
Malgré ces imperfections, la traduction s’est avérée très utile dans la grande majorité des cas, servant d’excellente première approche du texte. Les chercheurs soulignent que cette intelligence artificielle peut devenir un outil précieux pour les spécialistes ou les étudiants souhaitant approfondir l’étude de cette langue ancienne.
De plus, à mesure que cette technologie se démocratisera, il n’est pas irréaliste d’imaginer son intégration dans les salles de classe, les musées, ou encore au sein d’expériences historiques interactives. Cela permettrait au public d’interagir avec le passé d’une manière totalement inédite. Cette avancée offre un aperçu fascinant du potentiel qui réside à l’intersection de l’histoire et de la technologie, une synergie qui pourrait redéfinir notre compréhension de nos origines.
Cette étude a été publiée dans la revue scientifique PNAS Nexus.
Source : zmescience.com









{kind=link}